はじめに
前回の記事↓
前回の記事でやっと入力データとなるコーパスが完成したので、これからはモデル構築に入っていこうと思います。深層学習フレームワークとしてTensorFlowとPyTorchのどちらを使うか迷っていたのですが、色々調べた結果、PyTorchを使っていくことにしました。いくつかのニュース記事でPyTorchの人気が高まっていると見かけたので、せっかくだから伸びているほうを使ってみようと思った次第です。乗るしかない、このビッグウェーブに。
とりあえずPyTorchに慣れるために、参考書籍に載っているLSTMを使ったモデル(フレームワークは使っていません)をPyTorchを使って構築してみようと思ったのですが、これがなかなか苦戦しました。そこで今回はPyTorchを使ったLSTMモデルの実装をハマったところなども含めて紹介しようと思います。あくまでPyTorchの実装面の説明(というか自分用メモ)が中心なので、モデルの構造や用語の説明はしていません。後述の参考書籍を参照してください。
今回Pythonの実行環境にはGoogle Colaboratoryを使いました。Google Colabは初めて使ったのですがやっぱりGPUの計算スピードは驚異的でした。これまで自分のパソコンのCPU上で1日単位でかかっていた学習が、ColabのGPUを使えば数十分で終わるというこの速さ。しかもこのGPUが(時間制限はあれど)無料で使えるというのだから、Google先生には感謝です。
参考書籍はこれまで何度も紹介してきたコチラの本です。↓
ゼロから作るDeep Learning ❷ ―自然言語処理編 (Amazon)
PyTorchのドキュメントはコチラ↓
ドライブをマウント
ファイルの読み込みや保存ができるようにGoogle Driveをマウントしておきます。
from google.colab import drive
drive.mount('/content/drive')コードを実行するとURLが表示されるので、そこにジャンプして手に入れたパスワードを入力すればマウント完了です。
ライブラリのインポート
必要なライブラリをインポートします。Colabでは主要なライブラリはすでに用意されているので、importですぐにインポートできます。
import math
import matplotlib.pyplot as plt
import torch
print(torch.__version__)
import torch.nn as nn
import torch.optim as optim
!pip install -U torchtext
import torchtext
print(torchtext.__version__)
from torchtext import data, datasetstorchのバージョンは最新版だったのですが、データセットの読み込みに使うtorchtextというライブラリは古いバージョンだったので、pipで最新版をインストールしています。コマンドを実行する場合は先頭に!をつけるそうです。
このライブラリが最新版でないことに気づかなかったせいで結構ハマりました。やっぱりバージョン確認って大事ですね。
データセットの読み込み
torchtextライブラリを使ってPenn Treebank(PTB)データセットというコーパスを読み込んでいきます。PTBデータセットは語彙数1万の英語のコーパスで、自然言語処理の精度を測る指標としてよく用いられるそうです。
TEXT = data.Field(lower=True, batch_first=True,
eos_token='<eos>', pad_token=None)
train, val, test = datasets.PennTreebank.splits(TEXT)
TEXT.build_vocab(train)まず、TEXTというフィールド(?)を作成して、それを引数にしてPennTreebank.splits()を呼び出し、訓練データ、検証データ、テストデータを取得します。その後、trainデータから単語と単語IDが対応した辞書をbuild_vocab()というメソッドで作る、という流れです。
フィールドを作成する際の引数に、コーパスに対する処理をいろいろ指定しています。ここで指定しているのは、小文字化するlower=True、ミニバッチを作成する際にバッチ数を最初の次元にするbatch_first=True、文章の最後に<eos>を挿入するeos_token='<eos>'、パディングのために挿入される<pad>を使わないpad_token=Noneの4つです。ほかにもコーパスに対する処理をいろいろ指定できるようです。
build_vocab()で辞書を作ることによって、TEXT.vocab.itosやTEXT.vocab.stoiで辞書にアクセスできるようになります。例えばこんな感じです。
print(TEXT.vocab.itos[34])
>> have
print(TEXT.vocab.stoi['them'])
>> 127この辺りの処理はまだよく理解できていません。特にFieldクラスがよくわからない。。。詳しく知りたい方はドキュメントを参考にしてください。↓
モデルの定義
今回作るモデルの構造は下記のとおりです。参考書籍と全く同じモノを作ります。

自作のモデルをつくる場合はtorch.nn.Moduleを継承することになってます。__init__()内でレイヤーの作成と重みの初期化を行い、順伝播処理はforward()に記述しました。引数には語彙数、埋め込みベクトルの次元、隠れ層の次元、ドロップアウトの確率をとります。
class My_LSTM(nn.Module):
def __init__(self, vocab_size, emb_dim, h_dim, dropout):
super(My_LSTM, self).__init__()
self.embed = nn.Embedding(vocab_size, emb_dim)
self.drop1 = nn.Dropout(dropout)
self.lstm1 = nn.LSTM(emb_dim, h_dim, batch_first=True)
self.drop2 = nn.Dropout(dropout)
self.lstm2 = nn.LSTM(h_dim, h_dim, batch_first=True)
self.drop3 = nn.Dropout(dropout)
self.linear = nn.Linear(h_dim, vocab_size)
# 重みを初期化
nn.init.normal_(self.embed.weight, std=0.01)
nn.init.normal_(self.lstm1.weight_ih_l0, std=1/math.sqrt(emb_dim))
nn.init.normal_(self.lstm1.weight_hh_l0, std=1/math.sqrt(hidden_size))
nn.init.zeros_(self.lstm1.bias_ih_l0)
nn.init.zeros_(self.lstm1.bias_hh_l0)
nn.init.normal_(self.lstm2.weight_ih_l0, std=1/math.sqrt(emb_dim))
nn.init.normal_(self.lstm2.weight_hh_l0, std=1/math.sqrt(hidden_size))
nn.init.zeros_(self.lstm2.bias_ih_l0)
nn.init.zeros_(self.lstm2.bias_hh_l0)
self.linear.weight = self.embed.weight # 重み共有
nn.init.zeros_(self.linear.bias)
def forward(self, sentence, hidden1_prev, hidden2_prev):
emb = self.embed(sentence)
emb = self.drop1(emb)
lstm1_out, hidden1_next = self.lstm1(emb, hidden1_prev)
lstm1_out = self.drop2(lstm1_out)
lstm2_out, hidden2_next = self.lstm2(lstm1_out, hidden2_prev)
lstm2_out = self.drop3(lstm2_out)
out = self.linear(lstm2_out)
return out, hidden1_next, hidden2_nextここで注意点が4つあります。
1つ目はLinearレイヤの重みの形状です。通常、全結合層の重みは(入力数, 出力数)という形状の行列になります。しかしPyTorchでは全結合層(Linearレイヤ)の重みの形状は(出力数, 入力数)となっており、計算の際にはわざわざ転置しているようです。なぜこんな回り道をする仕様なのか気になって調べてみたところ、特に理由のない慣例だそうです。重み共有の際にEmbeddingレイヤの重みを転置していないのはそのためです。
2つ目はLSTMレイヤの引数のbatch_firstです。これをTrueにしない場合、出力の形状が(時系列長, バッチサイズ, 隠れ層の次元)という風にバッチサイズが最初に来ない形状になります。参考書籍ではバッチサイズを最初に持ってくる形で書かれていたので、それにそろえるためにTrueにしました。ちなみにLSTMレイヤにはnum_layersという引数があり、これでLSTMレイヤの数を2層にすることも(さらに間にドロップアウトをはさむことも)できるのですが、今回はわかりやすいように別のレイヤに分けました。
3つ目は重みの初期化です。これにはtorch.nn.initを使います。初期設定は一様分布になっているので、参考書籍とそろえるために重みは正規分布からランダムにとり、バイアスはゼロに設定しました。ドキュメントには他にも様々な初期化方法が紹介されています。↓
4つ目はforward()の中のLSTMレイヤの順伝播の返り値です。返り値は2つあり、lstm_out, hidden_nextとなっていますが、hidden_nextは隠れ状態と記憶セルのセル状態を含んだタプルになっています。
ドキュメントにはそれぞれのレイヤの入力と出力の形状の規則や、パラメータの種類などが詳しく乗っています。↓
ハイパーパラメータの設定
ハイパーパラメータの設定を行います。語彙数のvocab_sizeは前述したTEXTの辞書から取得しています。max_normは勾配クリッピングの時に使います。
max_epoch = 40
batch_size = 20
vocab_size = len(TEXT.vocab)
emb_dim = 650
hidden_size = 650
dropout = 0.5
bptt_len = 35
learning_rate = 20.0
max_norm = 0.25学習準備
モデルの精度を評価するためにデータからパープレキシティを評価する関数を先に定義しておきます。後述するモデルの学習処理とほとんど同じですが、逆伝播による勾配計算や最適化が無いのでwith torch.no_grad()を記述しておきます。勾配を計算しない分メモリが節約できるそうです。また、model.eval()でモデルを評価モードに変更しています。
# モデルを評価する関数
def eval_perplexity(model, iterator):
loss_sum = 0
hidden1, hidden2 = None, None
# 勾配を計算しないモードへ
with torch.no_grad():
# モデルを評価モードへ
model.eval()
for iters in iterator:
x, t = iters.text, iters.target
output, hidden1, hidden2 = model(x, hidden1, hidden2)
loss = criterion(output.view(-1, vocab_size), t.view(-1))
loss_sum += loss.item()
ppl = math.exp(loss_sum / len(iterator))
return pplさらに、モデルの作成、損失関数と最適化手法の設定、データのバッチ化を行います。損失関数には交差エントロピー誤差を、最適化手法にはSGDを(参考書籍通りに)選択します。
model = My_LSTM(vocab_size, emb_dim, hidden_size, dropout)
device = None
if torch.cuda.is_available():
model = model.cuda()
device = 'cuda'
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
train_iter, val_iter, test_iter = data.BPTTIterator.splits(
(train, val, test), batch_size=batch_size,
bptt_len=bptt_len, device=device)
print(len(train_iter))ここでは、torch.cuda.is_available()でGPUが使用可能かを判定しており、使用可能であればmodel.cuda()でモデルの全パラメータをGPUに移します。さらに、device = 'cuda'により、この後つくられるバッチ化されたデータもGPU上に作成されます。
損失関数はtorch.nnの交差エントロピー誤差のレイヤをcriterionとして使用します。
最適化を行うoptimizerは、torch.optimから好きな手法を選び、その引数にモデルのパラメータを渡します。
データのバッチ化には時系列データの逆伝播に対応したBPTTIteratorを使います。
学習の実行
学習の基本的な流れは次の5つの繰り返しになります。
1.勾配のリセット optimizer.zero_grad()
2.順伝播処理 output = model(x)
3.損失計算 loss = criterion(output, t)
4.逆伝播処理 loss.backward()
5.重み更新 optimizer.step()
この基本5つに、必要な処理をいろいろ加えたものがコチラのコードです。
# 損失の合計
loss_sum = 0
loss_count = 0
# パープレキシティのリスト
ppl_list = []
# 最良のパープレキシティ(初期値は無限大)
best_ppl = float('inf')
for epoch in range(max_epoch):
# モデルを訓練モードに設定
model.train()
hidden1, hidden2 = None, None
for i, iters in enumerate(train_iter):
# 入力データと教師データを取り出す
x, t = iters.text, iters.target
# 勾配をゼロにリセット
optimizer.zero_grad()
# 順伝播
output, hidden1, hidden2 = model(x, hidden1, hidden2)
# 損失計算
loss = criterion(output.view(-1, vocab_size), t.view(-1))
loss_sum += loss.item()
loss_count += 1
# 逆伝播
loss.backward()
# 勾配クリッピング
nn.utils.clip_grad_norm_(model.parameters(), max_norm)
# 重み更新
optimizer.step()
# 隠れ状態の計算グラフを消去
hidden1 = tuple(h.detach() for h in hidden1)
hidden2 = tuple(h.detach() for h in hidden2)
# 100イテレーションごとにパープレキシティを計算
if i % 100 == 0:
ppl = math.exp(loss_sum / loss_count)
ppl_list.append(ppl)
loss_sum, loss_count = 0, 0
print('| epoch {} | perplexity {:.2f} |'.format(epoch+1, ppl))
# 検証データで学習率を調整
val_ppl = eval_perplexity(model, val_iter)
print('| valid perplexity {:.2f} |'.format(val_ppl))
if best_ppl > val_ppl:
best_ppl = val_ppl
else:
learning_rate /= 4.0
for group in optimizer.param_groups:
group['lr'] = learning_rate注意点は主に7つあります。
1つ目はモデルを学習モードにするmodel.train()です。各エポックの最後にeval_perplexity()を呼び出した後、モデルは評価モードになっています。なので、このメソッドを呼び出してモデルを学習モードに戻しておきます。
2つ目は勾配のリセットです。PyTorchでは逆伝播で計算した勾配はどんどん累積されていくので、繰り返し処理の最初にゼロにリセットしておく必要があります。
3つ目は損失計算の際の引数の形状です。最初、出力を(バッチ数, 語彙数, 時系列長)、教師データを(バッチ数, 時系列長)という形状に変形して引数に渡していたのですがこれだと学習がうまくいきませんでした。ドキュメントを見ると一応この形状でも通るのですが、画像処理などで使うためのもののようでここで使うのは不適切っぽいです。そのため出力を(バッチ数×時系列長, 語彙数)に、教師データを(バッチ数×時系列長)に変形して渡しています。このことに気づかずにめちゃくちゃハマりました。ちなみに参考書籍のほうではちゃんとバッチ数と時系列長をまとめるように変形しています。(最初からその通りにやればいいものを。。。)
4つ目は勾配クリッピングです。勾配クリッピングにはtorch.utils.clip_grad_norm_()を使います。コードを記述する位置は逆伝播と重み更新の間です。逆伝播による勾配計算と、その勾配を使って重みを更新していることを考えればそこで勾配をクリッピングすることは当たり前なのですが、うっかり重み更新の後に書いてしまっていたことで学習がうまくいかなかったりしました。
5つ目はlossの値の取り出し方です。lossは値を一つだけ含むtorch.Tensorオブジェクトです。この場合、loss.item()とすることで損失の値をPythonの値として取り出すことができます。
6つ目は隠れ状態の計算グラフを消去することです。PyTrochのテンソルは自分がどのような過程をたどって計算されたのかという情報を計算グラフという形で保持しています。これを保持しているため、損失であるlossから逆伝播を行うことができます。それなので、hidden1やhidden2を繰り返し処理でそのまま渡してしまうと、backward()を呼び出した際にそれらの計算グラフをたどろうとしてエラーが出ます(一度loss.backward()で勾配計算した計算グラフは消去されるため)。そこで、タプルであるhiddenの中身を計算グラフを消去するためにそれぞれdetach()してから、新しいタプルとして生成しました。
7つ目は学習率へのアクセスの仕方です。エポックの終わりには参考書籍通りに検証データの評価による学習率の調整をしています。この時、学習率を書き換えるためにoptimizer.param_groupsに対して繰り返し処理を行っています。このparam_groupsは重み更新の対象のパラメータ(それぞれのレイヤの重みやバイアス)のグループで、それら一つ一つに対して学習率が個別に存在するようです。今回はすべての学習率を同じに設定していますが、特定のパラメータの学習率だけを変更することも可能っぽいですね。
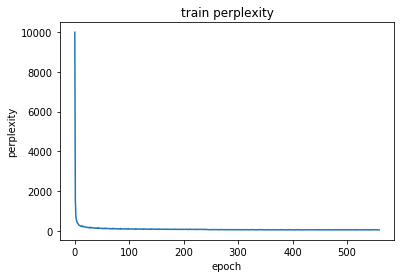
パープレキシティをプロット
matplotlibで訓練データに対するパープレキシティの推移をプロットします。
plt.plot(np.arange(len(ppl_list)), ppl_list)
plt.title('train perplexity')
plt.xlabel('epoch')
plt.ylabel('perplexity')
plt.show()結果はこんな感じです。かなり極端な形ですね。。。↓
テストデータで評価
テストデータを使ってパープレキシティを求めます。
ppl = eval_perplexity(model, test_iter)
print('| perplexity {:.2f} |'.format(ppl))結果は75.91となりました。参考書籍に載っている結果の値は75.76なので、少し大きいですがおおよそ一致しました。モデルが正しく学習できたということでしょう。(ただ何回やり直しても76近辺になって、75.76までは下がらなかったので少し気になる。。。)
おわりに
ハマりまくったのですごく疲れました。解決するまでの間、いろいろ試しまくってもパープレキシティが5000あたりをうろうろしていっこうに下がる気配がなかったので本当に途方にくれました。
ともあれ、なんとか正しくモデルを学習させることができてよかったです。次回から自作のモデルを作っていきます。(といっても今回のモデルとそんなに変わらないのですが。。。)
次回の記事↓

