はじめに
前回の記事↓
PyTorchを使ってLSTMモデルを実装する―RNNで文章生成〈8〉
いろいろ忙しくてかなり更新期間が空いてしまった。。。
前回の記事ではPyTorchに慣れるために、基本的なLSTMモデルをPyTorchを使って実装しました。そんなわけで大体PyTorchの使い方がわかったので次は自作のモデルをPyTorchで実装します。といってもこの記事を書いてる時点でもう目標の文章生成モデルは(一応)完成しています。しかし、完成したモデルによる文章生成の結果まで載せると記事が長くなりそうなので、今回はモデルの実装とその学習の説明だけを行い、次回の記事でこの文章生成モデルを使って実際に生成された文章をお披露目していきたいと思います。
PyTorchの基本的な実装など前回と被る部分はあまり説明しないです。
作業環境はGoogle Colaboratoryです。前回同様、無料でGPUを使わせてもらいます。
設計の変更点
第2回でモデルの設計図を紹介しましたが、実際に実装するに当たって少し変更を加えました。変更後のモデルをまとめたものが下図です(レイヤの名称もPyTorchに合わせました)。
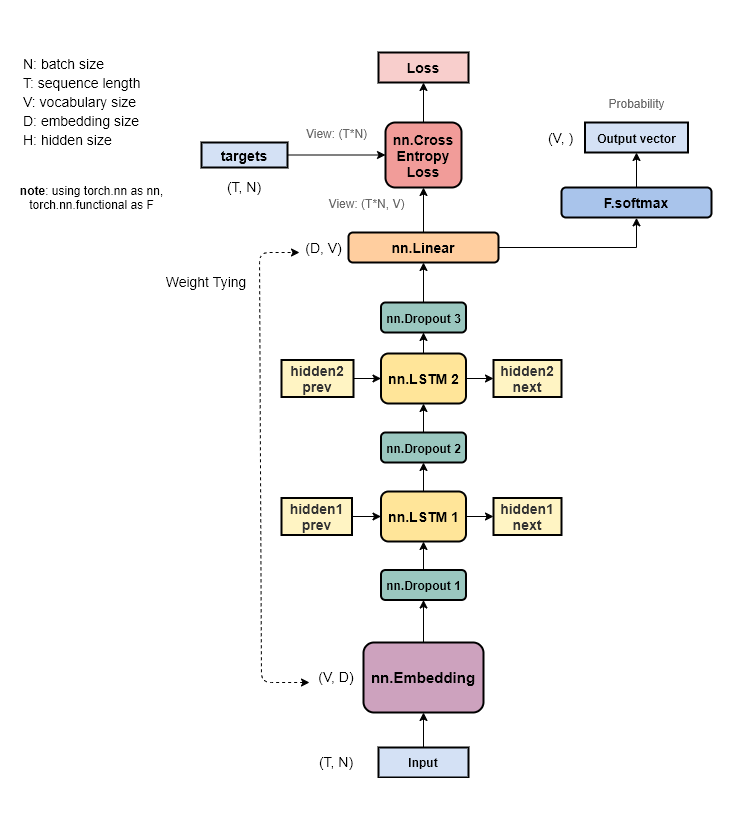
主な変更点は変分Dropoutをなくしたことです。これはPyTorchでの実装が難しそうだったのでいったん無しにしました。もちろん自分でレイヤをつくるなりして実装させることも可能でしょうが、とりあえず今回はライブラリに標準で用意されているものだけでやりました。なのでモデルの構造自体はEmbeddingレイヤに学習済みの重みを使う以外は前回のモデルと一緒です。また、推論時はLinearレイヤの出力をSoftmaxに通して確率に正規化します。
マウント&インポート
データ読み込みのためGoogle Driveにマウントし、必要なライブラリをインポートします。deviceをGPUの使用が可能ならば'cuda'に設定します。
from google.colab import drive
drive.mount('/content/drive')
import time, math, random, pickle
from pathlib import Path
import numpy as np
import matplotlib.pyplot as plt
import torch
print(torch.__version__)
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
device = 'cuda' if torch.cuda.is_available() else 'cpu'データの読み込み
これまでに作成した単語ベクトルや単語IDの辞書、入力データの読み込みを行います。これらのデータはGoogle Drive上に保存しておき、そこから読み込みます。先ほどマウントをしたので、drive/My Drive/でドライブ上のファイルに簡単にアクセスできます。
まず単語ベクトルを読み込んでいきます。第5回で日本語単語ベクトルChiVeをnumpy配列に変換し、npy形式で保存しておいたものを使います。語彙数は5万単語です。ただし、未知単語である<unk>に対する単語ベクトルが無いので、全単語ベクトルの平均(すなわち行の平均)を取ったものを<unk>に対応する単語ベクトルとして最後の行に挿入します。最後にnumpyからtorchの配列に変換して完了です。
filename = 'drive/My Drive/.../emb_layer_50k.npy'
with open(filename, 'rb') as f:
emb_layer = np.load(f)
# 末尾にの<unk>の単語ベクトルを挿入
unk_vec = np.sum(emb_layer, axis=0) / len(emb_layer)
emb_layer = np.append(emb_layer, unk_vec, axis=0)
embeddings = torch.tensor(emb_layer, dtype=torch.float, device=device)次に、同じく第5回で単語ベクトルと同時に作成し、pickle形式で保存した単語IDの辞書を読み込みます。こちらも<unk>に対応する組み合わせが存在しないので追加しておきます。
filename = 'drive/My Drive/.../word2id_50k.pkl'
with open(filename, 'rb') as f:
word_to_id = pickle.load(f)
# 単語IDから単語に変換する辞書も用意
id_to_word = {v: k for k, v in word_to_id.items()}
# <unk>を末尾に追加
dict_len = len(word_to_id)
word_to_id['<unk>'] = dict_len
id_to_word[dict_len] = '<unk>'最後に、第7回でようやく完成した入力データを読み込みます。入力データは青空文庫から取得した太宰治の小説を単語ごとに分割し、さらに単語IDに変換することで単語IDの配列にしたものです。小説ごとにnpy形式で保存されています。まずは一つの長編小説だけで学習させてみようかとも思ったのですが、データ数が少なかったので、すべての小説を連結して一つの大きな配列にすることにしました。それなので、別の小説の最後の部分と最初の部分が全く無関係であるにもかかわらず時系列が連続しているように入力されることになります。これは学習によくない影響をもたらす可能性がありますが、実装を簡略化するためとりあえず今回はこの入力方法で学習させてみたいと思います。
corpus = np.array([], dtype=int)
corpus_dir = Path('drive/My Drive/.../corpus')
for file_path in corpus_dir.glob('*.npy'):
if not file_path.exists():
print(file_path + ' does not exist!')
continue
with open(file_path, 'rb') as f:
corpus = np.concatenate((corpus, np.load(f)))
print(len(corpus))最後のコーパスの長さの出力は1385480となりました。
入力データの整形
入力データを訓練用(training)、検証用(validation)、テスト用(test)の3種類に分け、さらにミニバッチ化を行います。
まず、データの分割を行います。訓練データと検証データの比率を決めて、残りをテストデータにします。numpy配列からtorchの配列への変換も同時に行っています。PyTorchのレイヤでは整数データはLong型しか受け付けてくれないことが多いので、変換時はdtype=torch.longを引数で指定します。
train_ratio = 0.8
val_ratio = 0.1
size = len(corpus)
train_size = math.floor(size * train_ratio)
val_size = math.floor(size * val_ratio)
train = torch.tensor(corpus[:train_size], dtype=torch.long, device=device)
val = torch.tensor(corpus[train_size:train_size + val_size],
dtype=torch.long, device=device)
test = torch.tensor(corpus[train_size + val_size:],
dtype=torch.long, device=device)
print(len(train), len(val), len(test))訓練、検証、テストの長さはそれぞれ、1108384, 138548, 138548となりました。分割の比率はPTBデータセットの比率を参考にしました。↓
Penn Tree Bank (PTB) dataset introduction
次にミニバッチ化を行います。ミニバッチ化にはtorchtextというライブラリのIteratorクラスを参考にして、独自のイテレータ生成クラスを実装してみました。yieldを使ったジェネレータ関数を書くのは初めてだったので少し混乱しました。また、クラスメソッドも初めて使いました。参考先はコチラです。↓
SOURCE CODE FOR TORCHTEXT.DATA.ITERATOR
class MyBPTTIterator(object):
"""データを(時系列長, バッチサイズ)の形状で返す"""
def __init__(self, data, batch_size, bptt_len):
nbatch = data.size(0) // batch_size
data = data.narrow(0, 0, nbatch * batch_size)
self.data = data.view(batch_size, -1).t().contiguous()
self.batch_size = batch_size
self.bptt_len = bptt_len
@classmethod
def splits(cls, datasets, batch_size, bptt_len):
ret = []
for data in datasets:
ret.append(cls(data, batch_size, bptt_len))
return tuple(ret)
def __len__(self):
return math.ceil((len(self.data) - 1 ) / self.bptt_len)
def __iter__(self):
for i in range(0, len(self.data) - 1, self.bptt_len):
seq_len = min(self.bptt_len, len(self.data) - 1 - i)
text = self.data[i:i + seq_len]
target = self.data[i + 1:i + 1 + seq_len]
yield text, target
batch_size = 20
bptt_len = 35
train_iter, val_iter, test_iter = MyIterator.splits(
(train, val, test), batch_size, bptt_len)
print(len(train_iter), len(val_iter), len(test_iter))まずクラスメソッドについて説明します。クラス内のメソッドに@classmethodというデコレータをつけると、そのメソッドはクラスメソッドとなりインスタンス化していないクラスから直接呼び出すことができるようになります。第一引数がselfではなくclsになっており、ここにはクラス自体が渡されるようです。なので、メソッド内でcls(...)とすることでクラスをインスタンス化することができます。ここでは引数datasetsに渡された複数のデータセットから、それぞれのインスタンスを生成して返しています。こうすることでインスタンス生成時のコードがMyIterator.splits()の一行で済みます。
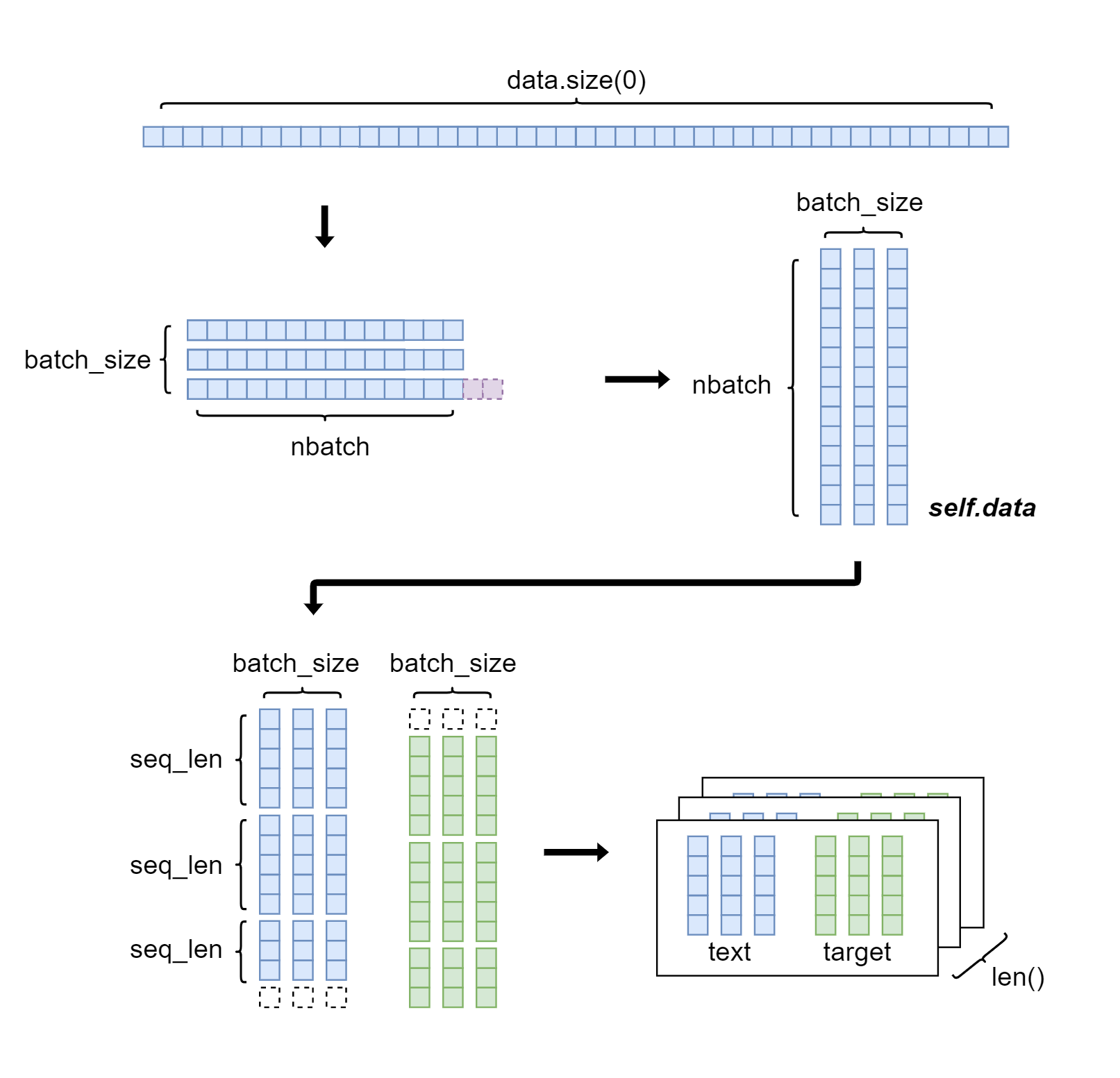
インスタンスを生成すると、__init__()で引数に渡された入力データを整形してself.dataとします。その後、for文のinに配置されるなどして__iter__()が呼ばれると、self.dataから時系列データを順番にスライスしていく仕組みです。文字では伝えにくいので画像で説明してみました(batch_size=3, bptt_len=5の場合)。
ジェネレータやイテレータに関してはいろいろと複雑でまだ完全に理解できていません。詳しくはこちらの記事などを参考にしてください。↓
ちなみにクラス名にIteratorとついていますがこのクラス自体は__next__()メソッドを持っていないので、Pythonでいうイテレータではありません(だと思います)。公式ドキュメントによるとジェネレータ型というらしいです。↓
訓練、検証、テストのミニバッチの大きさはそれぞれ、1584, 198, 198となりました。
モデルの構築
ニューラルネットワークモデルを構築します。前回のモデルとほとんど同じ実装ですが、少し変えているところもあります。
class MyLSTM(nn.Module):
def __init__(self, vocab_size, emb_dim, hidden_size, dropout,
embeddings=None, freeze=False):
super(MyLSTM, self).__init__()
# 学習済みの単語ベクトルを使う
if embeddings is not None:
weight_size = (vocab_size, emb_dim)
if embeddings.size() != weight_size:
raise ValueError(
f'Expected weight size {weight_size}, got {embeddings.size()}')
self.embed = nn.Embedding.from_pretrained(embeddings, freeze=freeze)
else:
self.embed = nn.Embedding(vocab_size, emb_dim)
self.dropout1 = nn.Dropout(dropout)
self.lstm1 = nn.LSTM(emb_dim, hidden_size)
self.dropout2 = nn.Dropout(dropout)
self.lstm2 = nn.LSTM(hidden_size, emb_dim)
self.dropout3 = nn.Dropout(dropout)
self.linear = nn.Linear(emb_dim, vocab_size)
# 重みの初期化
nn.init.normal_(self.embed.weight, std=0.01)
nn.init.normal_(self.lstm1.weight_ih_l0, std=1/math.sqrt(emb_dim))
nn.init.normal_(self.lstm1.weight_hh_l0, std=1/math.sqrt(hidden_size))
nn.init.zeros_(self.lstm1.bias_ih_l0)
nn.init.zeros_(self.lstm1.bias_hh_l0)
nn.init.normal_(self.lstm2.weight_ih_l0, std=1/math.sqrt(hidden_size))
nn.init.normal_(self.lstm2.weight_hh_l0, std=1/math.sqrt(hidden_size))
nn.init.zeros_(self.lstm2.bias_ih_l0)
nn.init.zeros_(self.lstm2.bias_hh_l0)
self.linear.weight = self.embed.weight # 重み共有
nn.init.zeros_(self.linear.bias)
def forward(self, input, hidden_prev):
if hidden_prev is None:
hidden1_prev, hidden2_prev = None, None
else:
hidden1_prev = hidden_prev[0:2]
hidden2_prev = hidden_prev[2:4]
emb_out = self.embed(input)
emb_out = self.dropout1(emb_out)
lstm1_out, hidden1_next = self.lstm1(emb_out, hidden1_prev)
lstm1_out = self.dropout2(lstm1_out)
lstm2_out, hidden2_next = self.lstm2(lstm1_out, hidden2_prev)
lstm2_out = self.dropout3(lstm2_out)
output = self.linear(lstm2_out)
hidden_next = hidden1_next + hidden2_next
return output, hidden_next前回のモデルからの変更点の一つはEmbeddingレイヤーに関するものです。先ほど読み込んだ単語ベクトルデータをモデルに渡して、それを使ったEmbeddingレイヤを作成しています。すでに学習済みの単語ベクトルを重みにする転移学習を行うことによって、学習効率が良くなる効果が見込めます。それに伴って引数にembeddingsとfreezeを加えています。freezeは、学習済みの重みを学習の段階で更新するか否かを決定します。どちらがいいのかはまだよくわからないのですが、とりあえずデフォルトはFalseにしておきました。もう一つの変更として2つのLSTMレイヤの隠れ状態を一つにまとめています。
その他の実装は前回のモデルと一緒です。重みの初期化方法も最適な方法とは限りませんがとりあえずそのままでいきます。
パープレキシティを評価する関数も実装しておきます。前回と同じものなので説明は省きます。
def eval_perplexity(model, iterator):
total_loss = 0
hidden = None
model.eval()
with torch.no_grad():
for input, target in iterator:
output, hidden = model(input, hidden)
loss = F.cross_entropy(output.view(-1, vocab_size), target.view(-1))
total_loss += loss.item()
ppl = math.exp(total_loss / len(iterator))
return pplモデルの学習
まず学習の準備を行います。モデルの引数に使う語彙数や埋め込み次元は用意したデータから取得します。それぞれ50001, 300となります。隠れ層の数、学習率、最適化手法などより良い結果を出すために考慮するべき点は多いですが、この辺りもとりあえず前回と一緒にしておきます。
vocab_size = len(word_to_id)
emb_dim = embeddings.size()[1]
print(vocab_size, emb_dim)
hidden_size = emb_dim
dropout = 0.5
learning_rate = 20.0
model = MyLSTM(vocab_size, emb_dim, hidden_size, dropout, embeddings)
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)準備が完了したら学習を実行します。先ほどミニバッチ化したtrain_iterを使った繰り返し処理でバッチ学習を行います。
max_epoch = 40
max_norm = 0.25
total_loss, loss_count = 0, 0
ppl_list = []
best_ppl = float('inf')
save_path = 'drive/My Drive/.../weight.pth'
for epoch in range(max_epoch):
model.train()
hidden = None
# 1エポックの実行時間を計測
start = time.time()
for i, iters in enumerate(train_iter):
input, target = iters
optimizer.zero_grad()
output, hidden = model(input, hidden)
loss = criterion(output.view(-1, vocab_size), target.view(-1))
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm)
optimizer.step()
hidden = tuple(h.detach() for h in hidden)
total_loss += loss.item()
loss_count += 1
if i % 500 == 0:
ppl = math.exp(total_loss / loss_count)
ppl_list.append(ppl)
total_loss, loss_count = 0, 0
# 検証データで評価
val_ppl = eval_perplexity(model, val_iter)
t = time.time() - start
print(f'| epoch {epoch+1} : valid perplexity {val_ppl:.2f} time {t:.2f}s |')
if val_ppl < best_ppl:
best_ppl = val_ppl
torch.save(model.state_dict(), save_path)
else:
learning_rate /= 4.0
for group in optimizer.param_groups:
group['lr'] = learning_rate学習率の更新方法としてもっとスマートな方法がないのか探しましたが、見つからなかったのでそのままです。変更点は検証データによるパープレキシティの評価を行う際に、結果が良かった場合モデルのパラメータを保存している点です。torch.save()とmodel.state_dict()を使うことが推奨されているようです。保存先はGoogle Driveです。実行時間の計測も追加しています。
最後に学習結果をプロットします。
plt.plot(ppl_list)
plt.ylim((0, 100))
plt.xlabel('iterations')
plt.ylabel('perplexity')
plt.title('train perplexity')
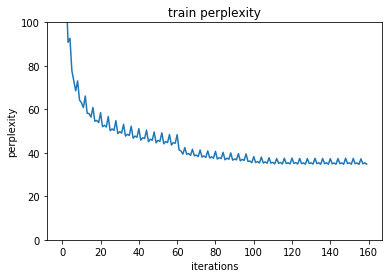
plt.show()学習を実行するとパープレキシティはこのように推移しました。
テストデータで評価
テストデータでパープレキシティを評価し、最終的な結果を見ます。
ppl = eval_perplexity(model, test_iter)
print(f'| test perplexity {ppl:.2f} |')結果は43.66でした。前回のPTBデータセットに対する結果は75.91だったので、これはかなりいい結果ではないでしょうか。もちろん、様々な新聞記事から作成されているPTBデータセットに対する結果と、単一の作家のみを入力にしている今回の結果は単純には比較できません。同じ作家の作品だと似た言い回しが多くなったりするのでその影響もあるかもしれません。
学習済み単語ベクトルの使用の有無や重み共有の有無などの条件を変えた場合に結果がどう変わるかは次の記事でまとめたいと思います。
おわりに
1月中に更新したかったのですが間に合わず2月になってしまいました。一か月間記事ゼロはブログとしていかがなものか。。。
ともあれ、学習が完了したのでいよいよ次回は太宰治風の文章を生成させてみたいと思います。お楽しみに。
次回の記事↓

